Та бүхэнд Oracle мэдээлэл сангийн систем дээр B-Tree индекс болон Bitmap индексийн харицуулсан судалгааг (B-Tree and Bitmap index) хийж үзсэнээ хуваалцаж байна. Ямар нөхцөлд аль индексийг хэрхэн хэрэглэх вэ гэдэг нь их чухал юм. Энэ бол эхний харицуулалт ба цааш нь үргэлжлүүлэн үзэх шаардлагатай болсон. Тайлбар тодорхойлолт зэргийг бусад эх үүсвэрүүдээс аван оруулсан.
Хэрвээ зав байвал Туршилтын хэсгийг оруулсан байгаа. 1 сая өгөгдөл оруулаад индексүүдийг үүсгэн, үр дүнг харах. :-)
Мэдээллийг хайх, хадгалах, өөрчлөх үед хурдан бөгөөд чанартай ажиллахад ашиглагддаг. Энэхүү аргачлал нь бүхий л шинжлэх ухаанд ашиглагдах боломжтой. Ихэнх индекс нь текстийн, бичиг баримтын болон медиа төрлийн эх үүсвэр лүү чиглэж байна.
Индексгүйгээр тухайн хайх зүйлийг бүх хэсгээс хайна. Энэ нь их хугацаа болон тооцоолол хэрэгтэй болно. Хайлтын архитектур нь дотроо дараах аргуудыг багтаасан байдаг.
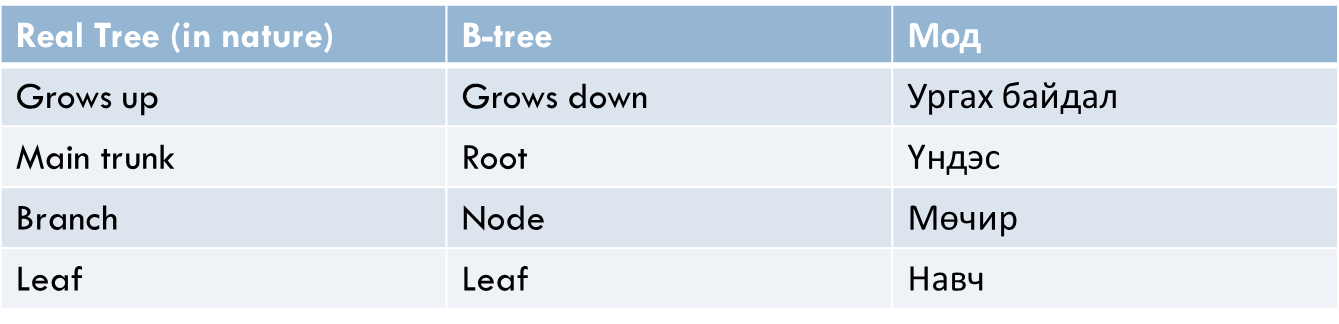
Харин доорх зурганд хоёртын мод болон Balanced B-Tree модны ялгааг харуулав.

*

*
2.2. Bitmap индекс
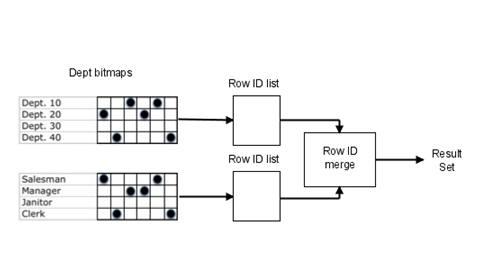
Oracle мэдээллийн сангийн энэхүү индекс нь B-Tree индексээс маш өөр болно. Энэхүү индексийн бүтэц нь хүснэгтийн баганад зориулан мөр болгоноор хоёр хэмжээст массив үүсгэдэг. Bitmap индексийн давуу тал бол хүснэгтийн маш олон баганаар индекс үүсхэд гарна. Хэрэглэгчээс ирж буй бүх төрлийн хүсэлтэнд саадгүй хариу үзүүлнэ. Жишээ нь: School гэсэн хүснэгтийн SchoolNo, SchoolName, SchoolAddress зэрэг баганаар үүсгэсэн бол энэ гурван талбарын альч талбаруудаар компинац зохион хайх боломжтой юм. Харин B-Tree индексийн хувьд ийм боломж байдаггүй.
Доорх зурагт энэхүү индексийн логик бүтцийг харуулсан болно.
Bitmap индексийн хамгийн тохиромжтой тохиолдолд нь статик хүснэгт болон materialized view тохиолдол юм. Нэг ёсны дээр нь ажиллаж байгаа тохиолдолд бичлэг шинээр нэмэгдэхгүй гэсэн үг юм. Мөн Bitmap индексийг үүсгэхдээ тухайн багана дахь өгөгдлийн давхацахгүй байх өгөгдлийн тоо юм. Жишээ нь: Primary талбар болон Gender талбар юм. Доорх статистикийг гаргасан байдаг. Жишээлбэл:
- 1 – 7 н давхацахгүй талбар байгаа бол query ажиллагаа маш хурдан болно.
- 8 – 100 н давхацахгүй талбар байгаа буюу давхацахгүй талбар ихсэж чадамж нь буурдаг болно.
- 100 – 10000 н давхацахгүй талбар байгаа буюу 100 аас даваад ирвэл чадамж нь хурдан буурна.
- 10000 аас их давхацахгүй талбартай бол маш удаан болно.
2.3. B-Tree болон Bitmap индексийн давуу болон сул тал
Oracle мэдээллийн сангийн B-Tree болон Bitmap индекс нь өөр өөрийн давуу болон сул талыг агуулж байдаг.
- Давуу
- Bitmap нь хайлт хурдан болно
- Bitmap нь тухайн баганаас хамаарч диск хэмжээ бага байна (Gender)
- Bitmap нь AD Hoc queryнд давуу талтай
- B-Tree нь диск хэмжээ бага байна
- B-Tree нь хайлтын баганууд тодорхой бол тухайн багануудаар үүсгэх боломжтой
- Сул
- Bitmap нь тухайн баганаас хамаарч диск хэмжээ их байна (Primary Key)
- Давхацахгүй талбарын тоо бага байснаар хурдан байна. Харин давхацахгүй талбар нь их бол маш удааг болно.
- B-Tree нь AD Hoc query – д тохиромжгүй
Мөн аль аль индексийн хувьд compress буюу үүсгэсэн индексийг шахаж кластер хэлбэртэй болгосноор хэмжээ болон хурданд шууд нөлөөтэй.
Доорх зурагт compress хийж хэрхэн мэдээллийг цэгцлэсэнг Bitmap индекс дээр харууллаа.
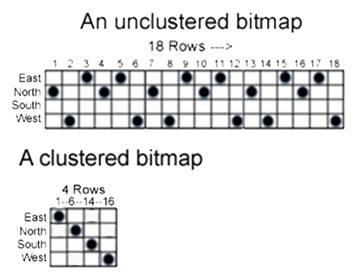
Дээрх хоёр төрлийн индексийг хариуцуулсан туршилтыг 1 сая өгөгдөл дээр хийсэн болно.
3. Туршилт
Oracle мэдээллийн сан дээр 1 сая бичлэгтэй хүснэгтийг дараах скриптээр үүсгэнэ.
Хүснэгт үүсгэх:
-----------------------------begin------------------------------------
Create table test_normal (empno number(10), ename varchar2(30), sal number(10));
-----------------------------end-------------------------------------
1 сая өгөгдлийг оруулах:
-----------------------------begin------------------------------------
Begin
For i in 1..1000000
Loop
Insert into test_normal
values(i, dbms_random.string('U',30), dbms_random.value(1000,7000));
If mod(i, 10000) = 0 then
Commit;
End if;
End loop;
End;
-----------------------------end-------------------------------------
3.1. Нарийвчлан харах хэсэг
Үүний дараа туршилтыг хэсгийг эхлүүлнэ. Ажиллуулсан query – н нарийвчлалтай гаргахын тулд доорх query – г ашиглана.
-----------------------------begin------------------------------------
declare
ltimestamp_start timestamp;
ltimestamp_stop timestamp;
linterval_diff interval day to second;
ldt_temp date;
empno NUMBER;
begin
ltimestamp_start := systimestamp;
dbms_output.put_line(ltimestamp_start);
Шалгах QUERY энэ хэсэгт байна.
ltimestamp_stop := systimestamp;
dbms_output.put_line(ltimestamp_stop);
linterval_diff := ltimestamp_stop - ltimestamp_start;
dbms_output.put_line(CHR(10)||LPAD('=',22,'=')||CHR(10));
dbms_output.put_line(' Runtime Difference'||CHR(10)||LPAD('=',22,'='));
dbms_output.put_line(
' Days : '||EXTRACT(DAY FROM linterval_diff)||CHR(10)||
' Hours : '||EXTRACT(HOUR FROM linterval_diff)||CHR(10)||
' Minutes : '||EXTRACT(MINUTE FROM linterval_diff)||CHR(10)||
' Seconds : '||EXTRACT(SECOND FROM linterval_diff) );
end;
-----------------------------end-------------------------------------
3.2. Туршилт 1
- Бичлэгийн тоо 1 сая
- B-Tree болон Bitmap индексийг Primary Key талбар дээр үүсгэсэн
Индексүүд Хэмжээ Хурд
B-Tree индекс 18MB 0.001 sec
Bitmap индекс 28MB 0.000 sec
3.2.1. Bitmap индекс үүсгэх болон үр дүнг харах
Доорх скриптүүдийг ажиллуулж индекс болон хэмжээг харна.
-----------------------------begin------------------------------------
create bitmap index normal_empno_bmx on test_normal(empno);
analyze table test_normal compute statistics for table for all indexes for all indexed columns;
select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" from user_segments where segment_name in ('TEST_NORMAL','NORMAL_EMPNO_BMX');
-----------------------------end--------------------------------------
Үүний дараа хайлтыг хийж үзэх шаардлагатай. Ингэснээр үр дүн гарна.
-----------------------------begin------------------------------------
Нарийвчлан харах хэсэг энд байна ….
select empno from test_normal where empno =565656;
Нарийвчлан харах хэсэг энд байна ….
-----------------------------end--------------------------------------
Bitmap индексийн үр дүн

3.2.2. B-Tree индекс үүсгэх болон үр дүнг харах
Доорх скриптүүдийг ажиллуулж индекс болон хэмжээг харна.
-----------------------------begin------------------------------------
drop index NORMAL_EMPNO_BMX;
create index normal_empno_idx on test_normal(empno);
analyze table test_normal compute statistics for table for all indexes for all indexed columns;
select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" from user_segments where segment_name in ('TEST_NORMAL','NORMAL_EMPNO_IDX');
-----------------------------end--------------------------------------
Үүний дараа хайлтыг хийж үзэх шаардлагатай. Ингэснээр үр дүн гарна.
-----------------------------begin------------------------------------
Нарийвчлан харах хэсэг энд байна ….
select empno from test_normal where empno =565656;
Нарийвчлан харах хэсэг энд байна ….
-----------------------------end--------------------------------------
B-Tree индексийн үр дүн

3.3. Туршилт 2
- Бичлэгийн тоо 1 сая
- B-Tree болон Bitmap индексийг Gender талбар дээр үүсгэсэн
Индексүүд Хэмжээ Хурд
B-Tree индекс 15MB 0.046 sec
Bitmap индекс 0.25MB 0.001 sec
3.3.1. Bitmap индекс үүсгэх болон үр дүнг харах
Доорх скриптүүдийг ажиллуулж индекс болон хэмжээг харна.
-----------------------------begin------------------------------------
alter table test_normal add GENDER varchar2(1);
update test_normal set gender = 'F' where empno >= 0 and empno <= 560000;
update test_normal set gender = 'M' where empno >= 560001 and empno <= 1000000;
create bitmap index normal_GENDER_idx on test_normal(GENDER);
select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" from user_segments where segment_name in ('TEST_NORMAL','NORMAL_GENDER_BMX');
-----------------------------end--------------------------------------
Үүний дараа хайлтыг хийж үзэх шаардлагатай. Ингэснээр үр дүн гарна.
-----------------------------begin------------------------------------
Нарийвчлан харах хэсэг энд байна ….
select count(*) into empno from test_normal where gender = 'F';
Нарийвчлан харах хэсэг энд байна ….
-----------------------------end--------------------------------------
Bitmap индексийн үр дүн

3.3.2. B-Tree индекс үүсгэх болон үр дүнг харах
Доорх скриптүүдийг ажиллуулж индекс болон хэмжээг харна.
-----------------------------begin------------------------------------
drop index normal_GENDER_idx;
create index normal_GENDER_idx on test_normal(GENDER);
analyze table test_normal compute statistics for table for all indexes for all indexed columns;
select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" from user_segments where segment_name in ('TEST_NORMAL','NORMAL_GENDER_IDX');
-----------------------------end--------------------------------------
Үүний дараа хайлтыг хийж үзэх шаардлагатай. Ингэснээр үр дүн гарна.
-----------------------------begin------------------------------------
Нарийвчлан харах хэсэг энд байна ….
select count(*) into empno from test_normal where gender = 'F';
Нарийвчлан харах хэсэг энд байна ….
-----------------------------end--------------------------------------
B-Tree индексийн үр дүн

3.4. Туршилт 3
- Бичлэгийн тоо 1 сая
- B-Tree болон Bitmap индексийг Primary Key болон Gender талбар дээр үүсгэсэн
Индексүүд Хэмжээ Хурд
B-Tree индекс 20MB 0.075 sec
Bitmap индекс 28.25MB 0.063 sec
3.4.1. Bitmap индекс үүсгэх болон үр дүнг харах
Индексийг үүсгэхдээ 3.2.1 болон 3.3.1 алхамуудыг хийнэ. Өмнөх үүсгэсэн индексүүдээ устгах шаардлагатай. Үүний дараа доорх QUERY ажиллуулна.
-----------------------------begin------------------------------------
select count(*) into empno from test_normal where gender = 'F' and empno between 15000 and 360000;
-----------------------------end--------------------------------------
Bitmap индексийн үр дүн

3.4.2. Bitmap индекс үүсгэх болон үр дүнг харах
Өмнөх үүсгэсэн индексүүдээ устгах шаардлагатай. Доорх скриптүүдийг ажиллуулж индекс болон хэмжээг харна.
-----------------------------begin------------------------------------
create index normal_GENDER_idx on test_normal(EMPNO, GENDER);
analyze table test_normal compute statistics for table for all indexes for all indexed columns;
select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" from user_segments where segment_name in ('TEST_NORMAL','NORMAL_GENDER_IDX');
-----------------------------end--------------------------------------
Үүний дараа хайлтыг хийж үзэх шаардлагатай. Ингэснээр үр дүн гарна.
-----------------------------begin------------------------------------
select count(*) into empno from test_normal where gender = 'F' and empno between 15000 and 360000;
-----------------------------end--------------------------------------
B-Tree индексийн үр дүн

Дүгнэлт
Oracle мэдээллийн системийн индексүүд нь бүгд хүчирхэг арга, техникүүд бөгөөд хэрэглэхдээ тухайн онцлого байдлаасаа хамааран хэрэглэх шаардлага гарна.
Bitmap индексийн хувьд:
Тухайн хэрэглэх гэж буй талбарын давхацахгүй өгөгдөл нь бага тохиодолд хамгийн тохиромжтой. Gender буюу цөөн төрлийн өгөгдөлтэй үед (Male, Female) тохиромжтой болсон. Хэмжээ бага, хурд өндөр. Давхацахгүй өгөгдөл нь 10000 дээш болбол хэрэглэх шаардлагагүй.
B-Tree индексийн хувьд:
Хэмжээний хувьд ямар ч төрөл байсан хоорондоо ойролцоо гарч байна. Харин хурдан байх, хэмжээ бага байх нөхцөл Primary Key талбар буюу хоорондоо давтагдахгүй байх тусмаа сайн. Мөн гаднаас ямар ямар талбараар хайх нь тодорхой бол хэрэглэвэл хамгийн тохиромжтой болно.
Зочилсонд баярлалаа. Ямар нэгэн асуулт байвал, коммент бичээрэй.
Хүндэтгэсэн,
Эрдэнэбаяр
Linkedin:
http://www.linkedin.com/in/erdenebayare
Twitter:
http://twitter.com/#!/erdenebayare